7. Métodos conexionistas
São métodos inspirados em modelos biológicos, que buscam não apenas simular o funcionamento do sistema nervoso humano e o modo como o cérebro adquire novos conhecimentos — ou seja, seu processo de aprendizado —, mas alcançar capacidade de processamento semelhante e obter máquinas inteligentes ou que se comportem de maneira aparentemente inteligente. Assim como o cérebro é composto por uma grande quantidade de neurônios interconectados, perfazendo redes neurais que funcionam em paralelo e trocam informações através de sinapses[1], as redes neurais artificiais (RNAs) são formadas por unidades que implementam funções matemáticas a fim de simular a atividade neuronal e, de modo geral, abstraem a compreensão da fisiologia do cérebro e dos processos biológicos de aprendizagem.
7.1 Redes neurais artificiais
"A procura por modelos computacionais ou matemáticos do sistema nervoso teve início na mesma época em que foram desenvolvidos os primeiros computadores eletrônicos, na década de 1940. Os estudos pioneiros na área foram realizados por McCulloch e Pitts (1943)[2]. Em 1943, eles propuseram um modelo matemático de neurônio artificial, a unidade lógica com limiar (LTU, do inglês Logic Threshold Unit), que podia executar funções lógicas simples. McCulloch e Pitts mostraram que a combinação de vários neurônios artificiais em sistemas neurais tem um elevado poder computacional, pois pode implementar qualquer função obtida pela combinação de funções lógicas. Entretanto, redes de LTUs não possuíam capacidade de aprendizado. [...] Na década de 1970, houve um resfriamento das pesquisas em RNAs, principalmente com a [...] limitação da rede Perceptron a problemas linearmente separáveis. Na década de 1980, o aumento da capacidade de processamento, as pesquisas em processamento paralelo e, principalmente, a proposta de novas arquiteturas de RNAs com maior capacidade de representação e de algoritmos de aprendizado mais sofisticados levaram ao ressurgimento da área." (FACELI et al., 2023, p. 102).
É possível definir as redes neurais artificiais como
"[...] sistemas computacionais distribuídos compostos de unidades de processamento simples, densamente interconectadas [...], conhecidas como neurônios artificiais, [que] computam funções matemáticas [...]. As unidades [neurônios artificiais] são dispostas em uma ou mais camadas e interligadas por um grande número de conexões, geralmente unidirecionais. Na maioria das arquiteturas, essas conexões, que simulam as sinapses biológicas, possuem pesos associados, que ponderam a entrada recebida por cada neurônio da rede [...] [e] podem assumir valores positivos ou negativos, dependendo de o comportamento da conexão ser excitatório ou inibitório, respectivamente. Os pesos têm seus valores ajustados em um processo de aprendizado e codificam o conhecimento adquirido pela rede (Braga et al., 2007)." (FACELI et al., 2023, p. 103).
7.1.1 Componentes básicos de uma RNA
Seus componentes básicos são arquitetura e e aprendizado. "Enquanto a arquitetura está relacionada com o tipo, o número de unidades de processamento e a forma como os neurônios estão conectados, o aprendizado diz respeito às regras utilizadas para ajustar os pesos da rede e à informação que é utilizada por essas regras." (FACELI et al., 2023, p. 103).
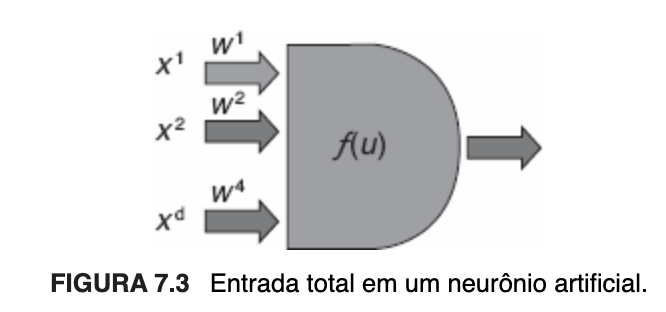
O neurônio artificial é a unidade de processamento e componente fundamental da arquitetura de uma RNA. Ele possui terminais de entrada que recebem os valores, uma função de ativação, que é uma função matemática que realiza o processamento desses valores já ponderados, e um terminal de saída que corresponde à resposta do neurônio, alusivos, respectivamente, aos dendritos, corpo celular e axônios de um neurônio biológico. A cada terminal de entrada corresponde um peso sináptico, sendo a entrada total, sobre a qual a função de ativação é aplicada, definida pelo somatório de cada um dos valores de entrada multiplicado pelo peso vinculado à conexão respectiva. Os terminais de entrada podem ter pesos positivos, negativos ou zero, neste caso indicativo de que nenhuma conexão foi associada.
A seguir, imagem ilustrativa de um neurônio artificial:
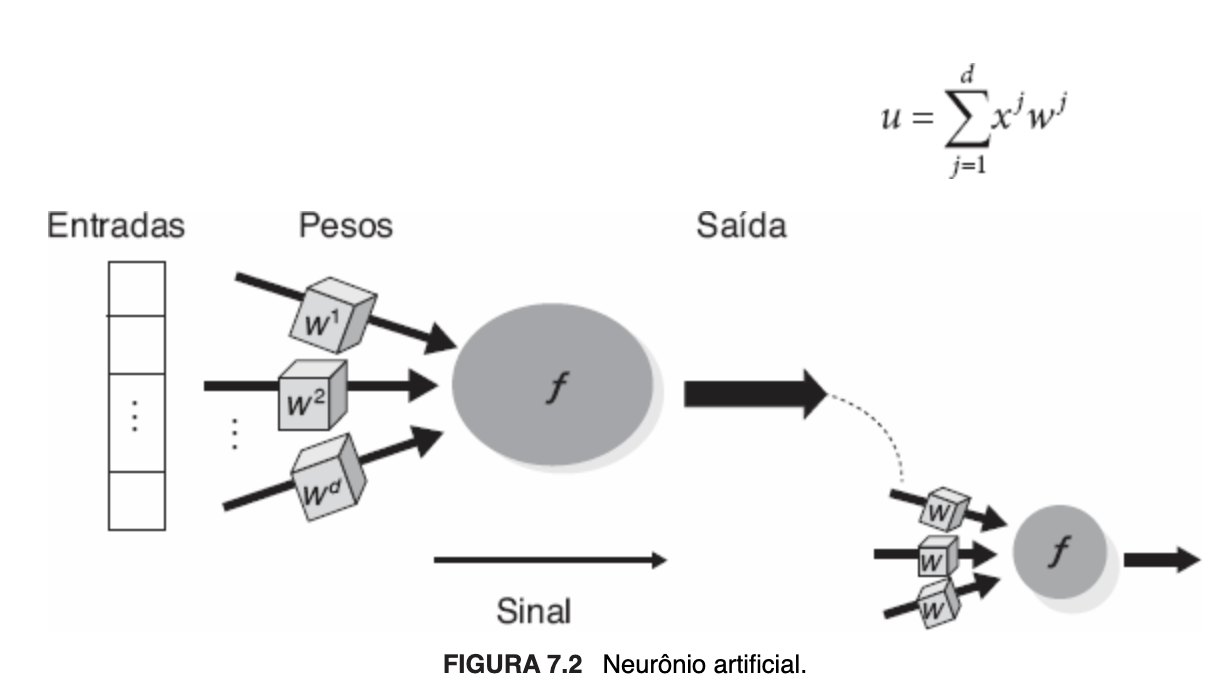
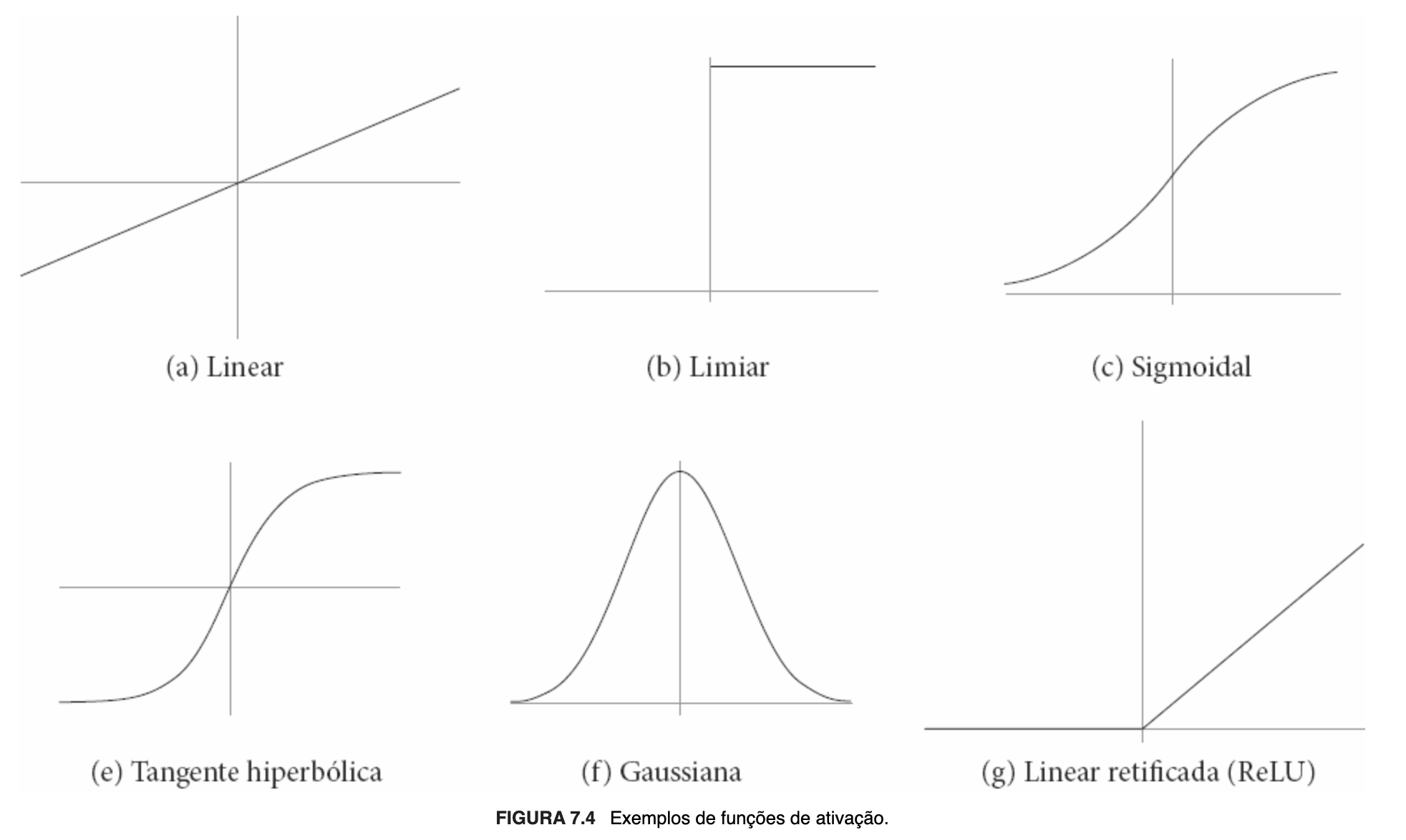
Em relação à função de ativação, dentre as propostas mais comuns, destacam-se as seguintes: linear, limiar, sigmoidal, tangente hiperbólica, gaussiana e linear retificada (ReLU). Em qualquer caso, ela receberá a entrada total e retornará um valor que será a saída do neurônio, definindo, por conseguinte, se ele será ou não ativado.
"O uso da função linear identidade [...] implica retornar como saída o valor de [ou seja, a própria entrada total]. Na função limiar [...], o valor do limiar define quando o resultado da função limiar será igual a 1 ou 0 (alternativamente, [...] -1). Quando a soma das entradas recebidas ultrapassa o limiar estabelecido, o neurônio torna-se ativo (saída +1). Quanto maior o valor do limiar, maior tem que ser o valor da entrada total para que o valor de saída do neurônio seja igual a 1. A função sigmoidal [...] representa uma aproximação contínua e diferenciável da função limiar. A sua saída é um valor no intervalo aberto (0, 1), podendo apresentar diferentes inclinações. A função tangente hiperbólica [...] é uma variação da função sigmoidal que utiliza o intervalo aberto (-1, +1) para o valor de saída. Outra função utilizada com frequência, também contínua e diferenciável, é a função gaussiana [...]. Mais recentemente, com a popularização das redes profundas, passou a ser cada vez mais utilizada a função linear retificada, também conhecida como ReLU (do inglês Rectified Linear Unit) [...]. Essa função retorna 0 se recebe um valor negativo ou o próprio valor, no caso contrário. Junto com suas variações, ela tem apresentado bons resultados em várias aplicações." (FACELI et al., 2023, p. 104, destaquei).
A seguir, imagens ilustrativas do cálculo da entrada total de um neurônio artificial e das precitadas funções de ativação:
7.1.1.1 Arquitetura
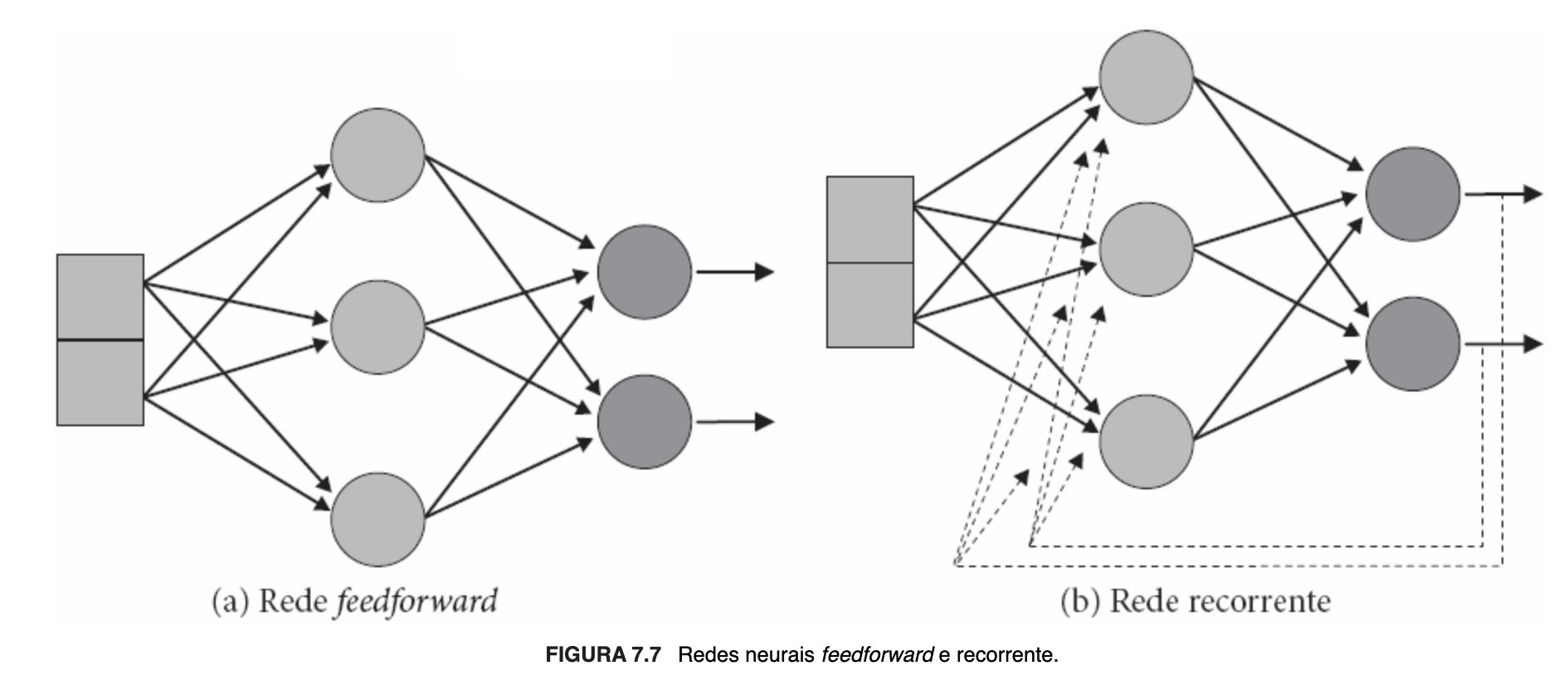
As redes neurais artificiais tem seus neurônios organizados em camadas que definem o padrão arquitetural da rede. Na forma mais simples, composta por uma única camada, os neurônios recebem os dados diretamente em seus terminais de entrada, correspondendo ela própria à camada de saída. Nas redes multicamadas, que possuem camadas intermediárias, escondidas ou ocultas, o fluxo da informação entre as camadas pode ser unidirecional (redes feed-forward) ou com retroalimentação (feedback) (redes recorrentes ou com retropropagação), isto é, um ou mais terminais de entrada de um ou mais neurônios recebem a saída de neurônios da mesma camada, de camada posterior ou mesmo a sua própria saída. "O número de camadas, o número de neurônios em cada camada, o grau de conectividade e a presença ou não de conexões com retropropagação definem a topologia de uma RNA." (FACELI et al., 2023, p. 106).
Ilustrando arquiteturas multicamadas sem e com retroalimentação, vejamos a imagem a seguir:
7.1.1.2 Aprendizado
Essencialmente, a capacidade de aprendizado está relacionada com o ajuste dos parâmetros da RNA, isto é, "[...] a definição dos valores dos pesos associados às conexões da rede que fazem com que o modelo obtenha melhor desempenho, geralmente medido pela acurácia preditiva." (FACELI et al., 2023, p. 106, destaquei). Isso é feito através de "[...] um conjunto de regras bem definidas que especificam quando e como deve ser alterado o valor de cada peso" (FACELI et al., 2023, p. 106, destaquei), implementadas por algoritmos de treinamento.
Os principais algoritmos são os seguintes: (1) correção de erro o ajuste é feito para minimizar os erros, geralmente, mediante o aprendizado supervisionado; (2) Hebbiano inspirado na aprendizagem Hebbiana — não supervisionada —, que preconiza o fortalecimento de conexões que, com frequência, são ativadas simultaneamente; (3) competitivo: os neurônios competem entre si (aprendizado não supervisionado); e (4) termodinâmico: inspirado na aprendizagem de Boltzmann, é um algoritmo estocástico que se baseia em princípios da Física (termodinâmica) e busca o "equilíbrio térmico" da rede.