Parte 2 | Modelos preditivos (capítulos 4 a 10)
6. Métodos simbólicos
Englobam modelos cujo objetivo é representar explicitamente, através de estruturas simbólicas[1], o conhecimento extraído do conjunto de dados. Esses métodos facilitam a interpretação do resultado por seres humanos, visto que asseguram "[...] uma compreensibilidade maior do processo decisório [...], estando mais alinhado[s] aos princípios de que os modelos de AM devem também ser 'explicáveis' (Explainable Machine Learning) para garantir maior transparência em sua operação." (FACELI et al., 2023, p. 78). Em contrapartida, se utilizados isoladamente, têm menor acurácia preditiva em comparação a outros modelos, ditos "caixa-preta"[2].
Não obstante, é importante destacar que, "atualmente, existem algoritmos eficientes para indução de árvores de decisão ou conjuntos de regras e de aplicação eficiente, com um desempenho equivalente ao de outros modelos (como redes neurais e SVM), mas com maior grau de interpretabilidade. [...] A combinação de múltiplos modelos de árvores em comitês (ensembles) também tem se mostrado competitiva e é uma abordagem frequentemente empregada para aumentar o desempenho preditivo desses modelos." (FACELI et al., 2023, p. 97).
6.1 Modelos baseados em árvores [3]
Os modelos baseados em árvores utilizam a estrutura de dados homônima para solucionar problemas de classificação ou regressão, casos em que os algoritmos são respectivamente denominados árvores de decisão ou árvores de regressão. Em ambos os casos, a forma de se interpretar o modelo e de construir o algoritmo indutor da própria árvore são bastante similares e, de modo geral, o problema é abordado recursivamente por meio da estratégia da divisão e conquista[4] sem backtracking.
"Usualmente, os algoritmos exploram heurísticas que localmente executam uma pesquisa olha para a frente um passo. Uma vez que uma decisão é tomada, ela nunca é reconsiderada. Essa pesquisa de subida de encosta (hill-climbing) sem backtracking é suscetível aos riscos usuais de convergência de uma solução ótima localmente que não é ótima globalmente. Por outro lado, essa estratégia permite construir árvores de decisão em tempo linear no número de exemplos." (FACELI et al., 2023, p. 80).
Nesse sentido, "um problema complexo é dividido em problemas mais simples, aos quais recursivamente é aplicada a mesma estratégia. As soluções dos subproblemas podem ser combinadas, na forma de uma árvore, para produzir uma solução do problema complexo. A força dessa proposta vem da capacidade de dividir o espaço de instâncias em subespaços e cada subespaço é ajustado usando diferentes modelos." (FACELI et al., 2023, p. 78).
"Formalmente, uma árvore de decisão[5] é um grafo direcionado acíclico em que cada nó ou é um nó de divisão, com dois ou mais sucessores, ou um nó folha." (FACELI et al., 2023, p. 79). Os nós de divisão possuem testes condicionais de acordo com o valor do atributo que representam; os nós folha são funções que representam as saídas do modelo, possuindo os valores da variável alvo. Cada nó da árvore corresponde a uma região no espaço definido pelos atributos.
"As regiões definidas pelas folhas da árvore são mutuamente excludentes, e a reunião dessas regiões cobre todo o espaço definido pelos atributos. A interseção das regiões abrangidas por quaisquer duas folhas é vazia. A união de todas as regiões (todas as folhas) é U. Uma árvore de decisão abrange todo o espaço de instâncias. Esse fato implica que uma árvore de decisão pode fazer predições para qualquer exemplo de entrada. [...] As condições ao longo de um ramo (um percurso entre a raiz e uma folha) são conjunções de condições e os ramos individuais são disjunções. Assim, cada ramo forma uma regra com uma parte condicional e uma conclusão. A parte condicional é uma conjunção de condições. Condições são testes que envolvem um atributo particular, operador [...] e um valor do domínio do atributo." (FACELI et al., 2023, p. 79).
Para exemplificar, vejamos a imagem a seguir:
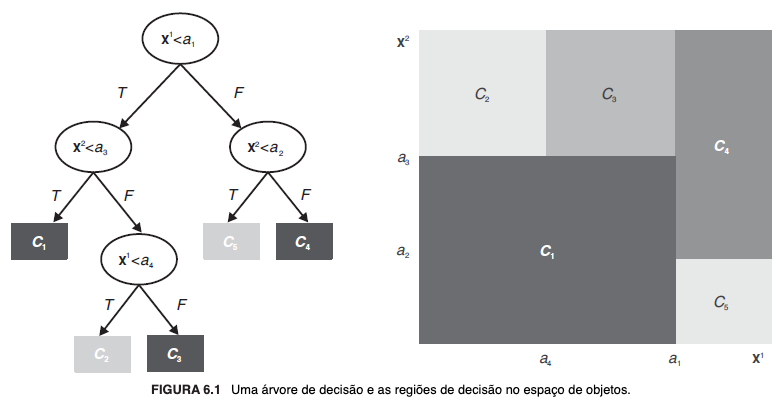
Os modelos baseados em árvores possuem vantagens como flexibilidade — por serem não paramétricos, não pressupõem alguma distribuição específica de dados[6] —, robustez — lidam bem com transformações de variáveis que preservem a ordem dos dados, não modificando a estrutura da árvore e a lógica do processo decisório[7] —, autonomia na seleção de atributos[8], interpretabilidade[9] e, em geral, eficiência[10]. Dentre as desvantagens, estão a replicação[11], a instabilidade[12] e a ineficiência em cenários específicos, como dados com valores ausentes[13] e atributos contínuos[14].
Há também modelos não convencionais como as árvores de modelos e de opções, alternativas que podem ser usadas em tarefas de regressão e classificação, respectivamente.
"Uma árvore de modelos (do inglês model tree) [...] combina árvore de regressão com equações de regressão. Esse tipo de árvore funciona da mesma maneira que uma árvore de regressão, porém os nós folha contêm expressões lineares em vez de valores agregados (médias ou medianas). A estrutura da árvore divide o espaço dos atributos em subespaços, e os exemplos em cada um dos subespaços são aproximados por uma função linear. A model tree é menor e mais compreensível que uma árvore de regressão e, mesmo assim, apresenta um erro médio menor na predição." (FACELI et al., 2023, p. 96, destaquei).
Em tarefas de classificação, as árvores de opção "[...] podem incluir nós de opção, que trocam o usual teste no valor de um atributo por um conjunto de testes, cada um dos quais sobre o valor de um atributo. Um nó de opção é como um nó ou em árvores e-ou. Na construção da árvore, em vez de selecionar o melhor atributo, são selecionados todos os atributos promissores, aqueles com maior valor do ganho de informação. Para cada atributo selecionado, uma árvore de decisão é construída. É de salientar que uma árvore de opção pode ter três tipos de nós: nós com somente um atributo teste - nós de decisão; nós com disjunções dos atributos de teste - nós de opção; e nós folhas." (FACELI et al., 2023, p. 97, destaquei). Em contrapartida, o consumo de recursos computacionais, notadamente memória e espaço para armazenamento, é substancialmente maior.
6.1.1 Regras de divisão em tarefas de classificação
As regras de divisão servem para atenuar a impureza dos conjuntos de dados e balizam a construção da árvore de decisão no intuito de maximizar a homogeneidade dos subconjuntos gerados em cada recursão, de modo que garantir a congruência dos atributos no tocante à seleção daqueles que melhor discriminam cada classe (goodness of split).
"Uma proposta natural é rotular cada subconjunto da divisão por sua classe mais frequente e escolher a divisão que tem menores erros" (FACELI et al., 2023, p. 81), e as diversas propostas para isso convergem para a conclusão de que "[...] uma divisão que mantém a proporção de classes em todo o subconjunto não tem utilidade, e uma divisão na qual cada subconjunto contém somente exemplos de uma classe tem utilidade máxima." (FACELI et al., 2023, p. 81).
Assim, a melhor divisão é aquela que minimiza a impureza e, consequentemente, heterogeneidade dos subconjuntos. Em sentido logicamente contrário, portanto, é de se concluir que a divisão ideal busca maximizar a homogeneidade dos dados em cada subconjunto.
Conforme Martin (1997), os autores distinguem as métricas para avaliar a qualidade das divisões em subconjuntos em três grandes grupos (funções de mérito), considerando diferentes critérios: (1) baseadas na diferença entre a distribuição de dados antes e depois da divisão, que enfatizam a pureza dos subconjuntos; (2) baseadas em diferenças entre os subconjuntos, cujo enfoque é a disparidade entre os subconjuntos após a divisão; e (3) baseadas na confiabilidade dos subconjuntos, isto é, em medidas estatísticas de independência capazes de denotar que cada nó/subconjunto (atributo) é efetivamente adequado para produzir boas previsões, em que a ênfase é no peso da evidência.
Embora não haja consenso em relação à superioridade, a escolha por algum critério parece ser superior à divisão aleatória de atributos.
Nas tarefas de classificação, as regras baseadas no ganho de informação e no índice de Gini são as mais comuns.
6.1.1.1 Baseadas no ganho de informação
Esta regra é baseada no conceito de entropia, que informa a aleatoriedade de uma variável isto é, quantifica a dificuldade de predizê-la. A entropia também pode ser compreendida como uma medida da desordem ou impureza do conjunto de dados, e é medida em logaritmos na base 2. Logo, quanto maior a entropia, mais difícil será predizer o valor dessa variável aleatória, e a árvore de decisão é construída de modo a minimizar a dificuldade de predizer a variável alvo.
"A cada nó de decisão, o atributo que mais reduz a aleatoriedade da variável alvo será escolhido para dividir os dados. [...] Os valores de um atributo definem partições [leia-se divisões] no conjunto de exemplos. Para cada atributo, o ganho de informação mede a redução na entropia nas partições obtidas de acordo com os valores do atributo. Informalmente, o ganho de informação é dado pela diferença entre a entropia do conjunto de exemplos e a soma ponderada da entropia das partições. A construção da árvore de decisão é guiada pelo objetivo de reduzir a entropia, isto é, a aleatoriedade (dificuldade para predizer) da variável alvo." (FACELI et al., 2023, p. 81).
Em cada nó de divisão da árvore, o atributo que mais reduzir a entropia, consequentemente maximizando o ganho de informação, será escolhido para resolver o subproblema — leia-se, a divisão em subconjunto naquela etapa recursiva. Logo, é esperado que a cada divisão ocorra a diminuição da aleatoriedade — incerteza em relação à classificação correta da variável alvo — em virtude da consistência dos atributos que conformam o subconjunto como sendo aqueles que melhor discriminam as classes.
Por isso é que, essencialmente, o ganho de informação consiste na redução da aleatoriedade resultante da diferença entre a entropia de todo o conjunto de dados e a dos subconjuntos.
6.1.1.2 Baseadas no índice de Gini [15]
É uma métrica de impureza dos nós de decisão (subconjuntos). Avalia a probabilidade de que exemplos escolhidos ao acaso pertençam a classes diferentes, mas estejam no mesmo subconjunto. Quanto menor o índice de Gini, mais homogêneo — e menos impuro — é o subconjunto. Nesse sentido, o atributo que melhor discrimina a classe é aquele que minimiza o índice de Gini e, via de consequência, reduz a impureza e aumenta a homogeneidade dos subconjuntos.
6.1.2 Regras de divisão em tarefas de regressão
Nas tarefas de regressão, o critério mais usual é calcular a média do erro quadrático (erro quadrático médio — EQM ou mean squared error — MSE), objetivando que dessa divisão resultem subconjuntos compostos por elementos cujos valores aproximem-se entre si, consequentemente minimizando o erro. "Por esse motivo, a constante associada às folhas de uma árvore de regressão é a média dos valores do atributo alvo dos exemplos de treinamento que caem na folha." (FACELI et al., 2023, p. 85).
Uma forma de avaliar a qualidade das divisões foi proposta por Breiman et al. (1984) e consiste na redução do desvio padrão (standard deviation reduction - SDR), a ser calculada para cada subconjunto possível, de modo que seja o que ensejar a menor variância.
6.1.3 Valores desconhecidos
Submeter valores desconhecidos ou indeterminados ao modelo, isto é, que não foram explicitamente contemplados dentre os dados de treinamento, pode levar a resultados indesejados, "uma vez que uma árvore de decisão constitui uma hierarquia de testes [...]" (FACELI et al., 2023, p. 86).
Para resolver o chamado problema do valor desconhecido, há na literatura diversas propostas, como (1) atribuir-lhe o valor mais frequente; (2) considerá-lo também um valor possível para o atributo em questão; (3) associar probabilidades a todos os possíveis valores do atributo (utilizada no algoritmo C4.5); ou (4) implementar a estratégia da divisão substituta, que preconiza a utilização de atributos que gerem divisões similares àquela obtida pelo atributo selecionado para criar uma lista alternativa de atributos, possibilitando a busca por outro, que corresponda ao valor desconhecido (utilizada no algoritmo CART).
6.1.4 Estratégias de poda
A poda de uma árvore de decisão (decision tree pruning) consiste na diminuição de seu tamanho, substituindo por folhas os nós demasiadamente profundos[16] (eliminação de ramos ou subárvores), com o objetivo de aumentar a confiabilidade do modelo e tornar o processo decisório ainda mais compreensível. O procedimento tende a melhorar a capacidade de generalização do modelo e é de especial importância em cenários com dados ruidosos.
"Dados ruidosos levantam dois problemas. O primeiro é que as árvores induzidas classificam novos objetos em um modo não confiável. Estatísticas calculadas nos nós mais profundos de uma árvore têm baixos níveis de importância em função do pequeno número de exemplos que chegam nesses nós. Nós mais profundos refletem mais o conjunto de treinamento (superajuste) e aumentam o erro em razão da variância do classificador. O segundo é que a árvore induzida tende a ser grande e, portanto, difícil para compreender." (FACELI et al., 2023, p. 86).
É possível realizar a poda concomitantemente à construção da árvore, interrompendo o processo conforme algum critério predeterminado, e outras que aguardam o término, respectivamente denominadas pré-poda e pós-poda. Não obstante, "tal como as regras de divisão, a poda é um domínio em que nenhuma proposta existente é a melhor para todos os casos. A poda é um enviesamento em direção à simplicidade. Se o domínio do problema admite soluções simples, então a poda é uma opção eficiente (Schaffer, 1993)." (FACELI et al., 2023, p. 88).
A pré-poda implementa regras que interrompem a construção de ramos que aparentemente não contribuiriam para incrementar a acurácia preditiva da árvore, evitando desde o início a criação de nós considerados inúteis, o que economiza tempo e recursos computacionais. Embora a literatura enumere diversas regras possíveis, são majoritariamente aceitas a assunção de que (1) todos os objetos que alcancem um determinado nó são da mesma classe e/ou de que (2) todos os elementos que o alcancem possuem características idênticas, embora não necessariamente pertençam à mesma classe.
Todavia, as estratégias de pós-poda são mais comuns e resultam em modelos mais confiáveis, embora o processo construtivo seja mais demorado porque "uma árvore completa, superajustada aos dados de treinamento, é gerada e podada posteriormente." (FACELI et al., 2023, p. 87). Logicamente que, por esse motivo, há maior consumo de tempo e recursos computacionais. Dentre os métodos de pós-poda, são elencados os (1) baseados nas medidas de erro estático e erro de backed-up; (2) a poda custo de complexidade, um dos mais utilizados, introduzido por Breiman et al. (1984) no algoritmo CART; e (3) a poda pessimista, apresentada e adotada por Quinlan (1988) no algoritmo C4.5[17].
6.2 Modelos baseados em regras
Uma regra de decisão compara logicamente um atributo e os valores conhecidos do domínio e, assim como nas árvores de decisão, seu espaço de hipóteses é dado sob a forma disjuntiva.
A despeito da grande semelhança, as regras de decisão flexibilizam algumas características inerentes às árvores de decisão que podem ser desvantajosas, como a replicação e a instabilidade, e tornam o processo decisório modular, visto que as regras podem ser avaliadas isoladamente, sem que modificações realizadas em determinada regra condicional afetem as subsequentes.
"Regras de decisão e árvores de decisão são bastante similares em suas formas de representação para expressar generalizações dos exemplos. Ambas definem superfícies de decisão similares. [...] Como as árvores de decisão cobrem todo o espaço de instâncias, a vantagem é que qualquer exemplo é classificado por uma árvore de decisão. Entretanto, cada teste em um nó tem um contexto definido por testes anteriores, definidos nos nós no caminho, que podem ser problemáticos se levarmos em conta a interpretabilidade. Por outro lado, as regras são modulares, ou seja, podem ser interpretadas isoladamente. Cada regra cobre uma região específica do espaço de instâncias. A união de todas as regras pode ser menor que o Universo." (FACELI et al., 2023, p. 90, destaquei).
Para exemplificar, vejamos a imagem a seguir:
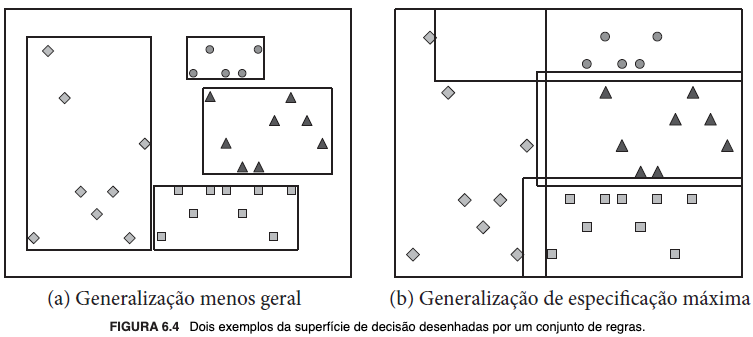
A similaridade permite a conversão de árvores em conjuntos ou listas de regras de decisão, tal que cada folha da árvore corresponda a uma regra. Embora a regra contemple o percurso por toda a altura da árvore — da raiz à folha —, é possível otimizar a representação, simplificando-a por meio da remoção de condições redundantes ou irrelevantes. Justifica-se essa abordagem:
"Árvores de decisão extensas são de difícil compreensão porque o teste de decisão em cada nó aparece em um contexto específico, definido pelo resultado de todos os testes nos nós antecedentes. O trabalho desenvolvido por Rivest (1987) apresenta as listas de decisão, uma nova representação para a generalização de exemplos que estende as árvores de decisão. A grande vantagem dessa representação é a modularidade do modelo de decisão e, consequentemente, a sua interpretabilidade: cada regra é independente das outras regras, e pode ser interpretada isoladamente das outras regras. Como consequência, a representação utilizando regras de decisão permite eliminar um teste em uma regra, mas reter o teste em outra regra. Além disso, como a conjunção de condições é comutativa, a distinção entre testes perto da raiz e testes perto das folhas desaparece." (FACELI et al., 2023, p. 91, destaquei).
Nesse sentido, o algoritmo de cobertura é capaz de aprender regras de decisão baseadas em exemplos e a qualidade das regras pode ser avaliada pela quantidade de casos cobertos, tenham ou não sido corretamente classificados.
"O algoritmo da cobertura define o processo de aprendizado como um processo de procura: dados um conjunto de exemplos classificados e uma linguagem para representar generalizações dos exemplos, o algoritmo procede, para cada classe, a uma procura heurística. Tipicamente, o algoritmo procura regras da forma: se Atributoi = Valorj e Atributol = Valork ... então Classez. A procura pode proceder a partir da regra mais geral, ou seja, uma regra sem parte condicional, para regras mais específicas, acrescentando condições [busca top-down orientada pelo modelo]; ou a partir de regras muito específicas [...] para regras mais gerais, eliminando restrições [busca bottom-up orientada pelos dados]. O processo de procura é guiado por uma função de avaliação das hipóteses. Essa função estima a qualidade das regras que são geradas durante o processo. [...] Dado um conjunto de exemplos de classes diferentes, o algoritmo de cobertura consiste em aprender uma regra para uma das classes, removendo o conjunto de exemplos cobertos pela regra (ou o conjunto de exemplos positivos), e repetir o processo. O processo termina quando só há exemplos de uma única classe." (FACELI et al., 2023, p. 91/92, destaquei).
Pode haver conflito entre duas ou mais regras, caso em que será necessário estabelecer algum critério de escolha. É importante observar que, diferentemente dos métodos bottom-up, os top-down induzem conjuntos ordenados de regras. Portanto, nestes, a execução do algoritmo é interrompida diante da primeira regra que satisfaça à condição de parada, enquanto naqueles, todas as regras aplicáveis são testadas e, normalmente, o resultado será ponderado pela qualidade de cada uma. Por esse motivo, é comum que algoritmos orientados por processos top-down contenham uma regra que específica para a classificação de exemplos desconhecidos.